Building Data Pipelines Like Assembly Lines
This is a story about a small team of data engineers at Astronomer who decided to stop hand-stitching every pipeline like artisanal Brooklyn cobblers and started building them like Ford Model Ts -- with interchangeable parts, quality control, and the confidence that comes from doing the same reliable thing over and over again. Not by working harder or being smarter, but by taking an industry pattern, write-audit-publish, and enforcing it ruthlessly with Airflow Task Groups and a DAG factory. We built a declarative framework for defining Airflow pipelines where tasks are self-documenting and metadata-driven. This let us focus on business logic – the SQL queries, Python functions, and data validations that actually matter – while a set of reusable Task Groups handles all the orchestration plumbing. Now we spend our time writing code that answers business questions, not writing boilerplate that wires up operators. And we deliver that code at ludicrous speed. ## The Problem: Imperative Pipelines Don’t Scale It’s a run-of-the-mill Tuesday morning and Marketing requests campaign attribution data. You unremarkably spend 3 days building a pipeline: hit the API, write to some cloud storage, load to your data warehouse, transform, publish. End of the week, all done, bring on the weekend. Two weeks later, Sales requests opportunity tracking. You spend 2 more days building essentially the same pipeline but just different enough that you can't reuse the code. We were solving the same fundamental challenge over and over, each time as if it were the first time. Each pipeline was a unique snowflake. Each snowflake had unique bugs. Each bug required unique debugging at unique hours. *The revelation*: Snowflakes are intricate structures which are ultimately completely random. They do not belong in data engineering. In our beforetimes, new datasets required a bespoke DAG to: * **Ingest**: Figure out where the data lives, how to pull it, how to land it. * **Transform**: Build the table, try not to break schemas, remember to add metadata (maybe). * **Validate**: Perhaps some tests, if we remembered and had time. * **Publish**: Hope the build pattern is consistent across DAGs and doesn't break dashboards. But, we realized that every new pipeline we built was secretly four things: 1. A way to *write* the data. 2. A way to *audit* it. 3. A way to *publish* safely. 4. And a handful of environment‑specific hacks so dev and production wouldn't eat each other alive. You can do that once or twice by hand. Do it a hundred times and you either need to build abstractions or you start leaving little notes in the codebase like a trapped character in a Kurt Vonnegut novel. We chose abstractions. ## The Pattern: Write-Audit-Publish In our warehouse, every dataset follows the same three-act structure: **I: Write to staging** Never touch production directly. Never. Write to a temporary location where failure is cheap and mistakes are private. **II: Audit the staging data** Test everything. Check everything. Validate that reality matches expectations. If it doesn't, stop. Use the temporary dataset to dig in and figure out what went wrong, then go fix it. Most of the time it’s better to have stale data than *wrong* data. **III: Publish atomically** If the tests pass, swap the staging data into production in one atomic operation and document the dataset. Either it works or it doesn't. No half-measures. No "mostly correct" data. Simple in theory. The trick is making it impossible to bypass. So, we encoded the pattern into reusable components so thoroughly that building a pipeline any other way feels like punishment. *Enter*: Airflow Task Groups and a DAG-factory pattern to automatically generate DAGs from simple file declarations. ## The Factory Floor The core idea: **tasks should be declarations, not implementations**. Instead of writing Python code to wire up operators, connections, and dependencies, we write files that declare: * What data we're working with and how it should be produced * What it means (documentation) * What must be true about it (tests and validations) * Where it lives (schemas, tables) * How it should behave (environment-specific config) Our DAGs are generated from these declarations. We built this using a directory-based convention where each folder becomes a DAG and each file becomes a task, with frontmatter driving the behavior. ### What a Declarative Task Looks Like Building a model, ingesting data from an API, etc. is simply a SQL or Python file with YAML frontmatter that declares metadata and behavior. For example, this builds a dataset for a ledger of daily transactions in our data warehouse: ```sql /* operator: include.task_groups.transform.CreateTable description: >- Cleaned table of credit balances per credit grant, does not include estimated daily consumption. This is the official ledger, transactions against the credit grants only occur when invoices process or manual deductions are created. fields: date: >- Date within credited period (between effective date and expiration date of credit). metronome_id: Unique identifier of the organization in Metronome. credit_item_id: ID of credit item, credits can have multiple grants. granted_amt: Credit amount granted on date. consumed_amt: Credit amount consumed on date. expired_amt: Credit amount that expired on date. voided_amt: Credit amount that was voided on date. start_amt: Credit balance at the start of day. end_amt: Credit balance at the end of day. priority: >- Order in which the credit is applied if two of the same name exist on a given day. schema: !switch_value sandbox: sandbox_schema default: model_finance replace_map: commons: !switch_value sandbox: dev.commons default: commons primary_key: - credit_item_id - date foreign_keys: credit_item_id: model_finance.credit_grants.credit_item_id metronome_id: model_finance.metronome_ids.metronome_id tests: check_condition: - description: >- End amount should be the summation of changes that occurred that day. sql: > TO_NUMBER(start_amt + granted_amt - consumed_amt - voided_amt - expired_amt, 20, 2) = end_amt - description: Check for date gaps in credit balance sql: > COUNT(date) OVER (PARTITION BY credit_item_id) = MAX(date) OVER (PARTITION BY credit_item_id) - MIN(date) OVER (PARTITION BY credit_item_id) + 1 */ SELECT ... SQL here ... ``` **This frontmatter is the entire specification.** It describes: * *Which Task Group to use* (`CreateTable`) - the orchestration pattern * *What the table means* (`description`, `fields`) - self-documenting * *What must never be broken* (`primary_key`, `foreign_keys`, `tests`, `validations`) - quality gates * *Where it lives* (`schema` that’s environment-aware) - deployment config
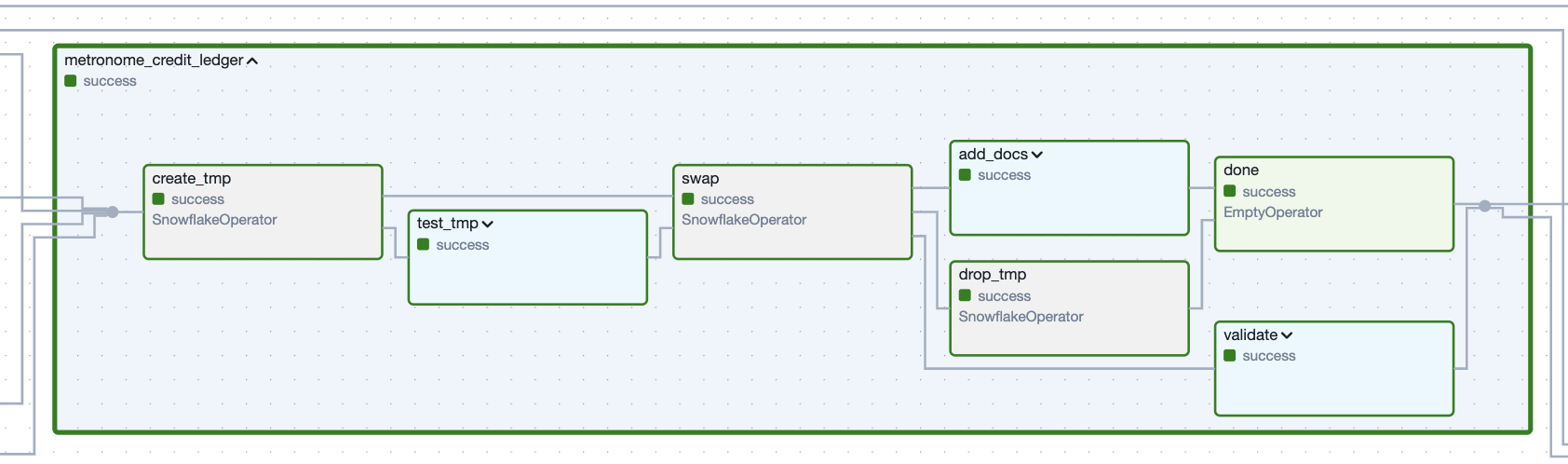 Figure 1. The Task Group which creates the ledger dataset defined by the example code snippet.
Figure 1. The Task Group which creates the ledger dataset defined by the example code snippet.
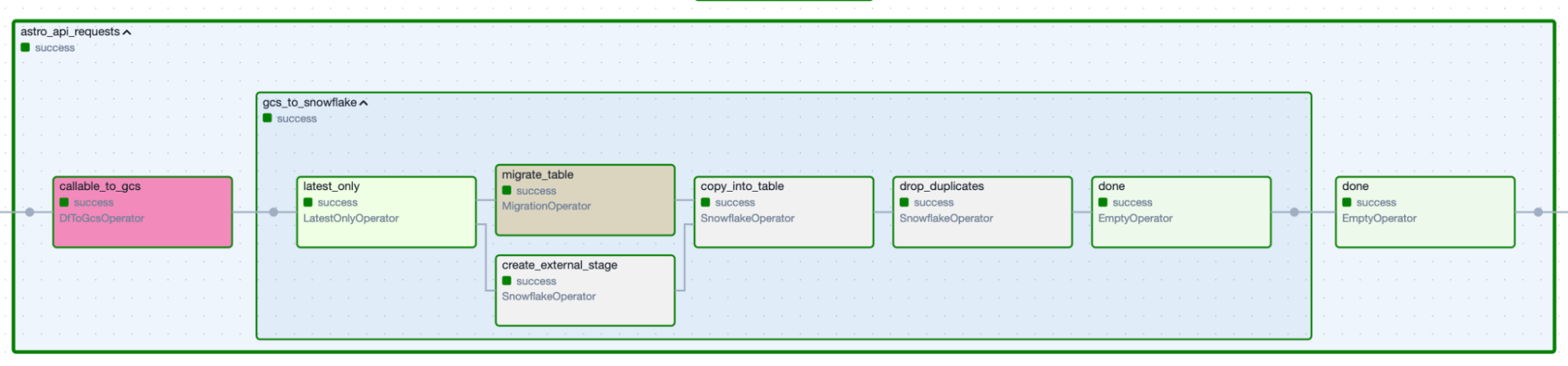 Figure 2. Data-ingestion Task Group produced by the specification above.
Figure 2. Data-ingestion Task Group produced by the specification above.
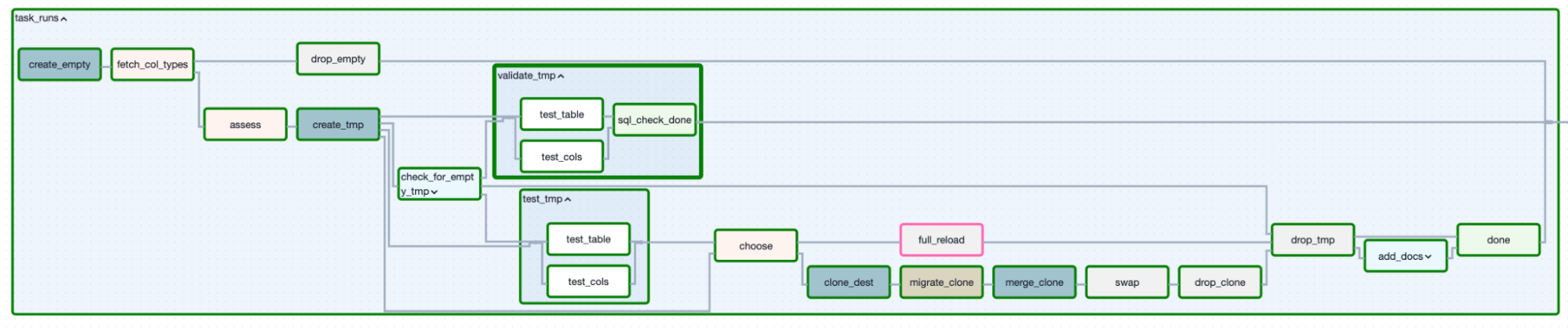 Figure 3. Incremental loading determined a decision-based approach.
Figure 3. Incremental loading determined a decision-based approach.
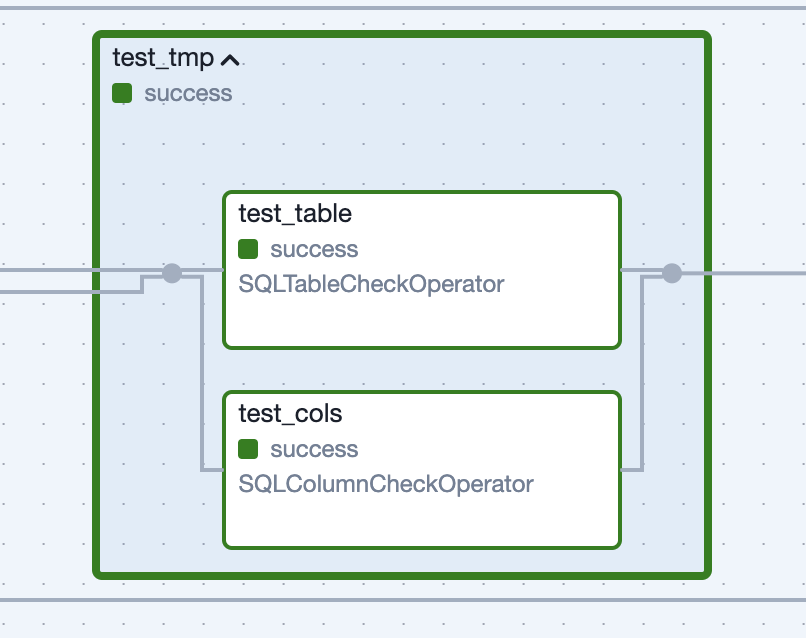 Figure 4: Task Group generated for tests run against the unpublished dataset.
Figure 4: Task Group generated for tests run against the unpublished dataset.
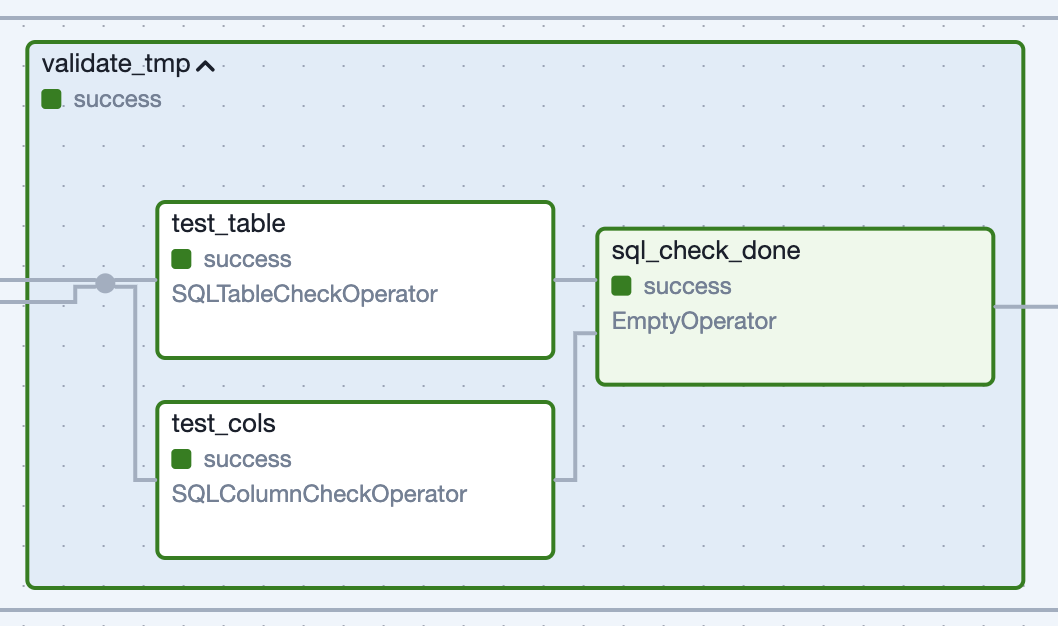 Figure 5: Task Group generated for “soft validations” run against the published dataset.
Figure 5: Task Group generated for “soft validations” run against the published dataset.
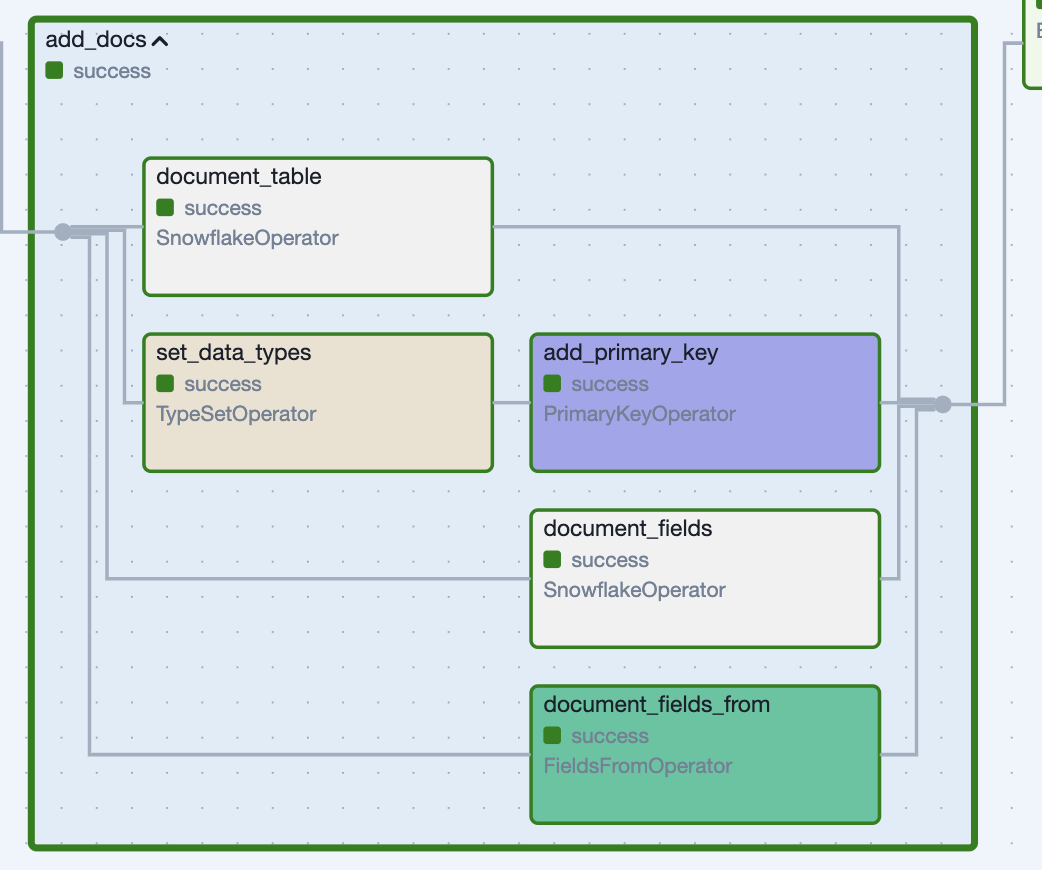 *Figure 6: Applying documentation and constraints with a Task Group.*
*Figure 6: Applying documentation and constraints with a Task Group.*

Get started free.
OR
API Access
Alerting
SAML-Based SSO
Airflow AI Assistant
Deployment Rollbacks
Audit Logging
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.