The AI Agent Behind Astro Runtime's Reliability
11 min read |
About the author: Kaxil Naik is an engineering leader at Astronomer and a PMC member & Committer of the Apache Airflow project.
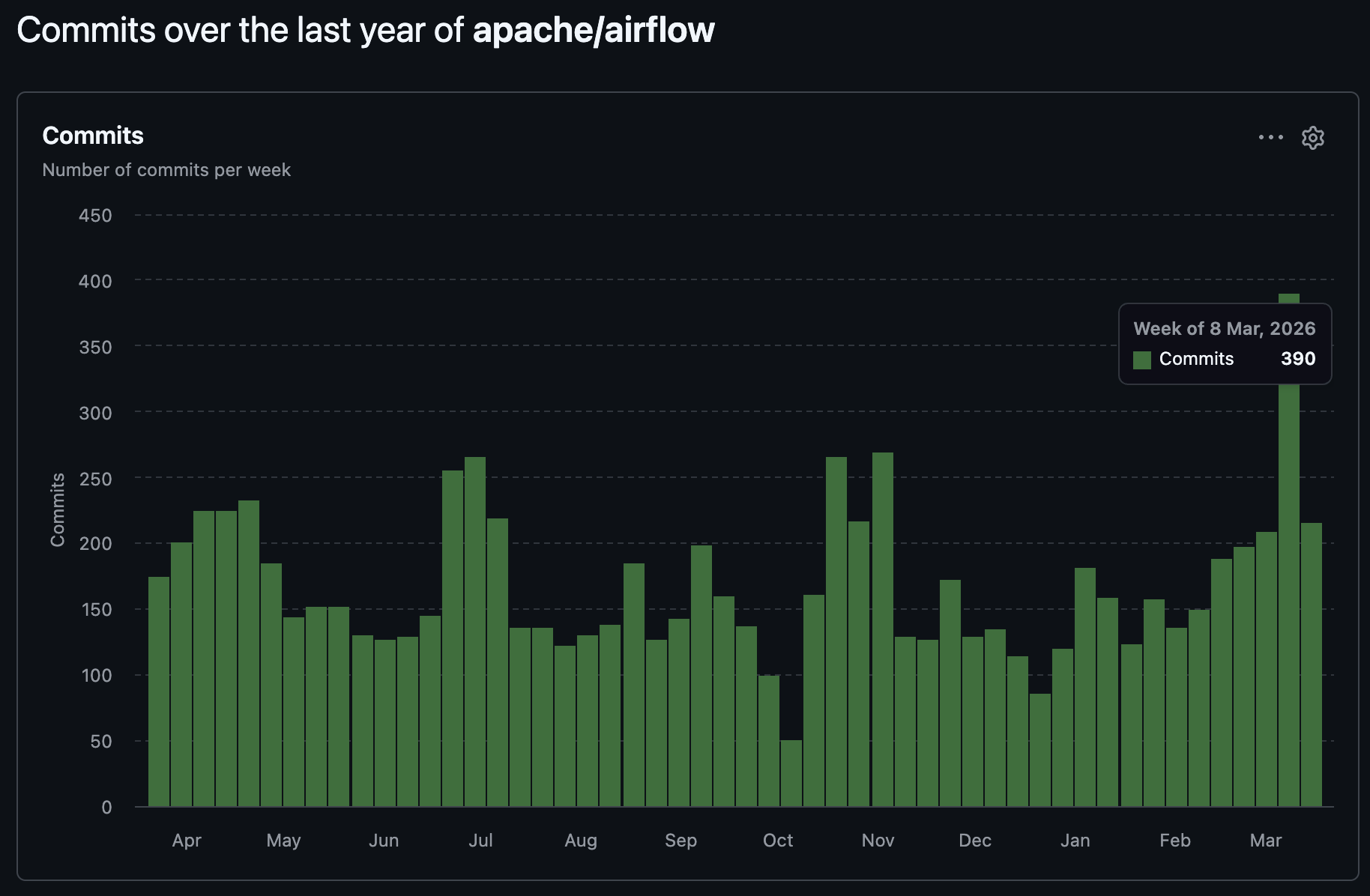
Apache Airflow moves fast. On the main branch alone, 20 to 80 commits land every day. That's fine if you pull a stable release every few months. It's a different problem if you're Astronomer.
We don't just run Airflow. We ship it. Astro Runtime is a curated distribution of Airflow with our own components layered on top: an Astro Executor, a Kubernetes executor, a custom auth manager, remote logging handlers, and a migration tool called Starship. Eight downstream repositories depend on Airflow's internals -- its ORM models, scheduler loop, executor interfaces, serialization layer, REST API, plugin system. We track 31 import paths across those repos. When upstream changes a function signature, renames a class, adds a non-nullable column, or removes a method we're calling, things break. Often silently.
The coupling is intentional. We build on Airflow's internal interfaces because that's how we add managed execution, remote logging, custom auth. But any upstream change, in any release, might break something of ours. Airflow doesn't follow semver for internal interfaces -- these are implementation details that happen to be Python imports, not a public API with stability guarantees.
Not everything we catch is about our code, though. Some changes are behavior regressions that affect anyone running Airflow -- open-source users, self-managed deployments, customer DAGs. The February scheduler incident below wasn't about our code at all. It was an upstream bug that would crash any scheduler at sufficient scale. When we find those, we push fixes back upstream.
For a long time, we caught breaks during release testing. An engineer would pull a batch of Airflow changes into our fork, build Runtime, run CI, and find out what had gone wrong. Sometimes CI caught it. Sometimes a customer caught it first. Days between the upstream change and our awareness of it, weeks before a fix shipped. And the review itself was a slog -- skimming hundreds of commits, holding the dependency graph in your head, hoping you didn't miss anything.
So we built an AI agent that reads every Airflow commit, every day, and tells us which ones will break our stuff. Out of ~1,200 commits per month, maybe two produce an action item. Those two would have become customer incidents.
An Example Incident
A while back, we had an example of an incident play out that drove us to reconsider our release management process- the scheduler would start, run for a few minutes, get killed by its liveness probe. Restart, crash, restart, crash. Over 50 restarts in 16 hours.
Three days of pg_locks and strace later, we found the root cause: a single upstream PR that had made three seemingly benign changes:
- Removed a fast-exit guard from ReadyToRescheduleDep. Previously, only reschedule-mode sensors hit the database for reschedule history. After the change, every task instance did.
- Mutated a shared context object.
are_dependencies_met()calleddep_context.deps.add(ReadyToRescheduleDep())when a task wasUP_FOR_RESCHEDULE. The scheduler creates oneDepContextand reuses it for all task instances in a batch. Once one reschedule task added the dep, it ran for every subsequent task instance -- even those that had nothing to do with rescheduling. - No index on the query path. The
task_rescheduletable didn't have a composite index on(ti_id, id DESC). Each query scanned 900,000+ rows at ~340ms.
Do the math at a sample customer's scale: 2,000 tasks per DAG run, 20 DAG runs per scheduler loop, 340ms per query. That's 2,000 x 20 x 0.34 = ~13,600 seconds per loop. The scheduler's liveness threshold was 120 seconds.
We added a composite index. Query time dropped from 342ms to 0.019ms -- 18,000x. The upstream fixes landed in three PRs.
Three interconnected issues -- the removed guard, the shared mutable state, the missing index.
Our Runtime Release Agent
It's worth noting that the system we built to catch these changes is designed to be implemented as an Airflow DAG- every day, it pulls the latest commits from apache/airflow, compares them against our last-checked state, and runs a five-phase analysis.
Phase 1: Triage. Each commit gets deterministically classified by which paths it touches. SKIP for docs, tests, UI-only, providers we don't use. TARGETED for monitored paths unlikely to break us. FULL for anything we directly import or subclass. This is rule-based -- the agent knows which 31 paths matter and routes accordingly. On a typical day, 60-80% of commits skip.
Phase 2: Pattern scan. The commit runs against our pattern library -- 18 classes of breaking change. We seeded these from past incidents, but the agent also proposes new ones when it hits novel failure modes. Each pattern has a concrete detection script. (More on patterns below.)
Phase 3: Impact analysis. For each flagged commit, the agent greps the downstream code to find specific call sites. Not "this commit touches models, and we use models" -- it finds where we call the changed method, where we match on the renamed type string.
Phase 4: Verification. The agent traces the call chain: upstream function changed here, we call it here, the mismatch means this at runtime. Then it suggests a fix. In March 2026, when upstream restored a batch of ORM columns to nullable, the agent grepped our Kubernetes executor code, found an unguarded .get() call on a now-nullable field, and pointed to the exact line and the OSS commit that fixed the same issue.
Phase 5: Adversarial review. A separate subagent re-reviews the analysis. We added this because the primary analysis was producing false positives -- flagging changes as breaking when they weren't. The adversarial reviewer pushes back, verifies reasoning, and either confirms or downgrades. It works both directions: on one check, it upgraded a finding from MEDIUM-HIGH to HIGH after confirming a guaranteed crash.
The engine is Claude Code with a structured knowledge base. The LLM matters less than the knowledge base. An LLM reading a git diff without context is a fancy diff command. An LLM reading a git diff with import maps, pattern history, architecture invariants, and incident post-mortems catches what we missed.
What the agent knows
The knowledge base has three layers.
Import maps. The agent scans each downstream repo and extracts every Airflow module, class, and function it imports. Not a static list we maintain by hand -- the agent refreshes this from source code. It knows one repo imports from airflow.executors.workloads import TaskInstance, another subclasses a DAG processing manager, a third matches on callback request type strings. When upstream renames TaskInstance to TaskInstanceDTO, the agent tells us which files in which repos break and how.
Breaking change patterns. Eighteen patterns, each from a real incident or near-miss:
- Pattern M: Discriminated union type renames. In January 2026, a change upstream renamed
EmailNotificationRequesttoEmailRequest(the old name exceeded a 20-character DB column limit). Our code matched on the old type string in a polymorphic query. Email callbacks silently dropped. No error, no crash, just missing notifications. - Pattern Q: Scheduler hot-path query performance. Added after the February incident. When a change touches the scheduler's per-task-instance dependency loop, the agent checks: does this query run inside a per-TI loop? Is the table indexed for this access pattern? What happens at 900,000 rows?
- Pattern N: Eager loading for boolean checks. A
joinedload(DagVersion.task_instances)loaded every task instance just to checkif dag_version.task_instances:. At scale, that's an OOM. We now flag any relationship load used only for existence checks. - Pattern B: Required field becomes optional. ORM columns go from
Mapped[str]toMapped[str | None]. Code without null guards crashes. In March 2026, we caught this when a batch of fields were restored to nullable, and confirmed the upstream Kubernetes executor needed the same fix.
Architecture invariants. Four rules that must always hold, like "the scheduler loop must complete within 120 seconds" (INV-004, violated in the February incident) and "DagModel.bundle_version must equal the current bundle version after every parse" (INV-001, violated by a caching bug that took 10 months to fully fix -- workers were running old DAG code).
The learning loop

Now, incidents don't just get fixed, they get fed back into the system.
Within days of the post-mortem, we added Pattern Q (scheduler hot-path query performance), a variant of Pattern A (shared mutable state in loops), and invariant INV-004 (scheduler loop timing). We documented the scale factors: N_TIs x N_dagruns x per_TI_time. We wrote detection rules so the agent would catch similar changes. Pattern Q's checklist now asks: "Does this query run inside a per-TI loop? What's the call count at scale? Is the query covered by an appropriate index?"
That's the cycle. Incident happens, post-mortem identifies the class of problem (not just the specific bug), new pattern gets added, daily checks start scanning for it.
It's not only incidents. When the agent under-rates something or produces a false positive, we adjust. The scheduler change that removed ReadyToRescheduleDep's fast-exit guard? We looked at the diff, saw a dependency check being simplified, called it low risk. Didn't consider what happens when that "simplified" check runs for every task instance at scale. After the incident, the agent knows to ask that question.
The same loop produced patterns from near-misses that never became incidents. Pattern N came from an OSS PR that loaded every task instance through a joinedload just to evaluate a boolean. We caught the OOM risk during analysis, not in production.
The system self-prunes too. We track when each pattern last detected something real. Patterns C, E, H, and M have flagged issues as recently as March 2026. Patterns A, D, F, and K have never fired in two months. After 90 days without a hit, a pattern becomes a candidate for removal. Better to have 12 patterns that match real problems than 18 with six generating noise.
What the output looks like
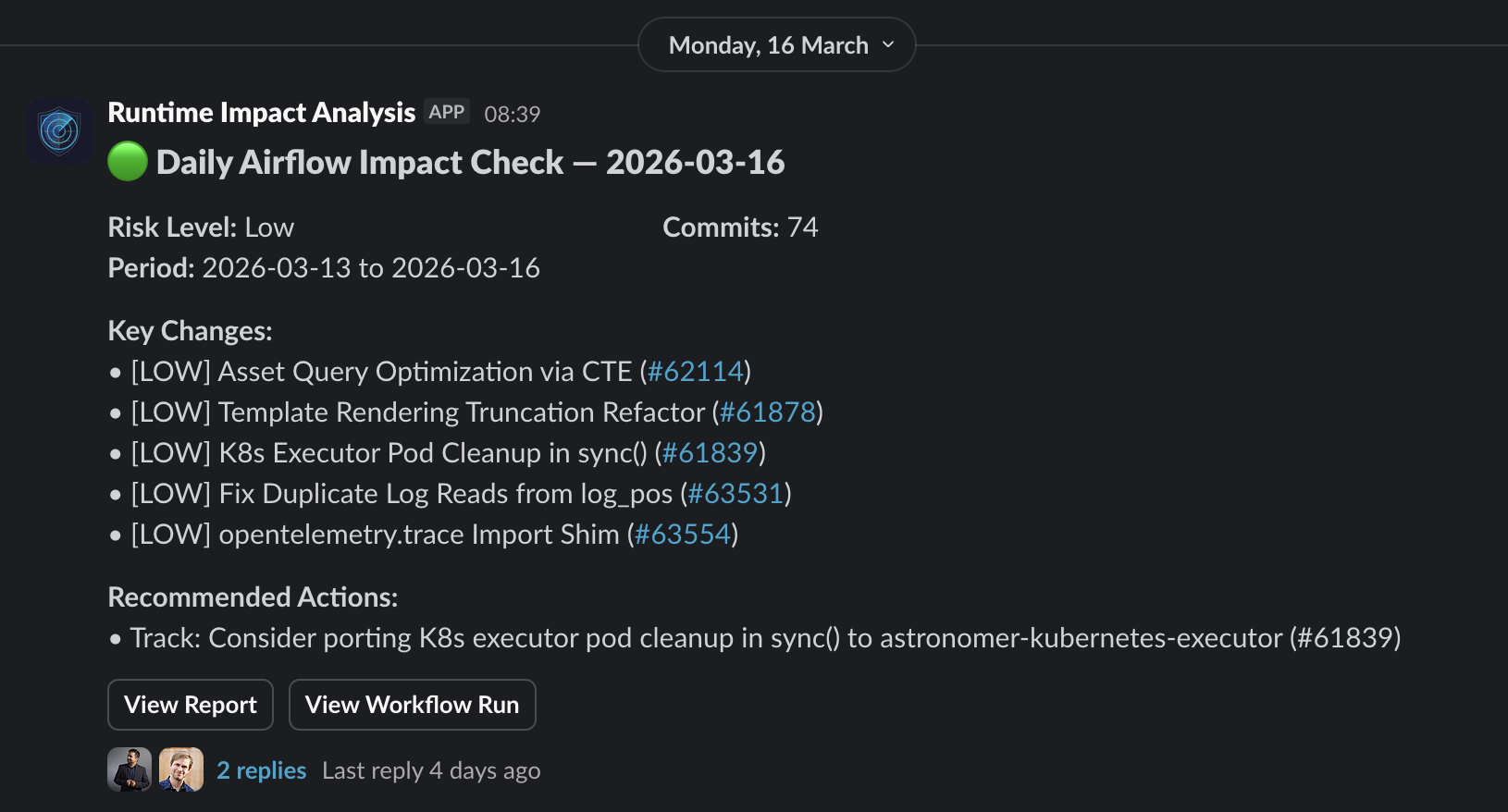
Most days are quiet. March 16: 74 commits, 60 skipped, 14 analyzed, zero breaking changes. An engineer reviews the report in two minutes and moves on.
March 17 was different. 29 commits, one verified HIGH. An upstream PR changed an Airflow base class so that a field we access at startup was replaced with a stub that raises RuntimeError until a new init method runs. One of our components accesses that field before the new init. The report traced the call chain, identified the guaranteed crash, cited the PR, and suggested a one-line fix. We had it ready before the change reached any Runtime build.
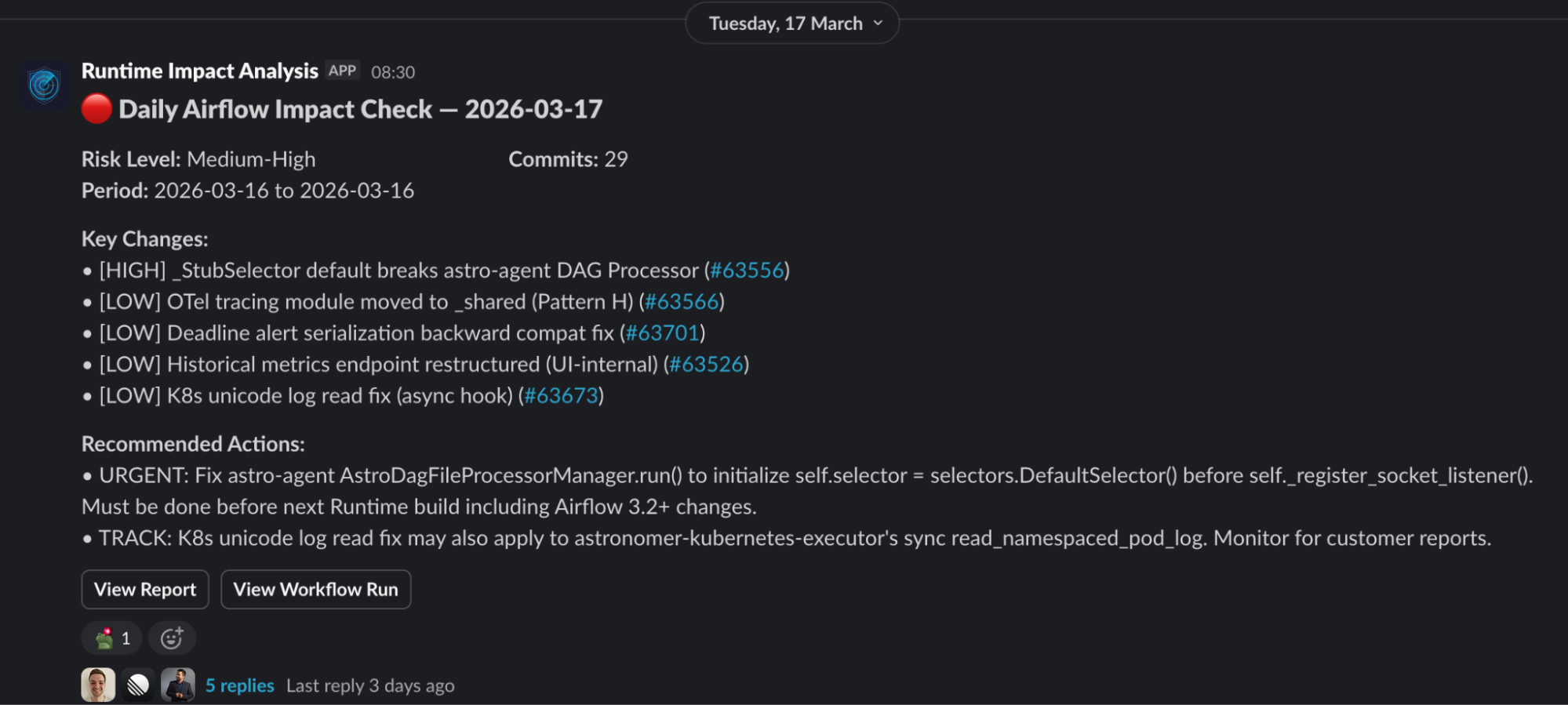
~1,200 commits per month, maybe two action items. Those two would have been customer incidents otherwise.
Where this leaves us

Before: breaking changes found during release testing, or after customers hit them. Days to weeks of lag. Now: the morning after they land upstream, with call chains traced and fixes suggested.
The agent has run daily since mid-January 2026. Thousands of commits across 18 patterns and 31 paths. The patterns are the real product -- not the LLM, but the accumulated knowledge of what breaks and why, in a form a machine can apply every day without forgetting to check index coverage on a hot-path query.
The tedious work runs automatically. Engineers focus on judgment calls: is this finding a real problem at our customers' scale? What's the right fix? Patch locally or push upstream?
The system gets sharper over time. Patterns grow from incidents and near-misses. Patterns that stop matching get pruned. Every pattern traces back to something real -- scar tissue, encoded as detection rules.
This is work somebody has to do whenever Airflow upgrades. If you self-manage Airflow, that somebody is you. If you're on a managed service that wraps Airflow without deep integration, upstream changes still reach you -- they're just not caught until they do.
We do this because Astro Runtime extends Airflow with components that depend on its internals. We have to understand every upstream change at a level of detail most operators never need to. When we find bugs like the February scheduler issue, we fix them upstream. Astro Runtime customers get those fixes as soon as we've validated them. For open-source users, the fix lands in the next Airflow release, following the Apache release process (review, vote, publish). The agent shortens the window on our side; contributing upstream shortens it for everyone.
The agent is one piece of that. But the real investment is the knowledge behind it: 18 patterns from real incidents, 31 monitored paths, four architecture invariants, and a team that treats every miss as a chance to make the system better. That's what ships with every Runtime release.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.