Info
This page has not yet been updated for Airflow 3. The concepts shown are relevant, but some code may need to be updated. If you run any examples, take care to update import statements and watch for any other breaking changes.
DuckDB is an open-source in-process SQL OLAP database management system. It allows you to run complex queries on relational datasets using either local, file-based DuckDB instances, or the cloud service MotherDuck. The ability to create a local DuckDB instance is useful for testing complex Airflow pipelines without the need to connect to a remote database.
Airflow can interact with DuckDB in two key ways:
Other ways to learn
There are multiple resources for learning about this topic. See also:
- Webinar: How to use DuckDB with Airflow.
- Example repository: Astronomer’s DuckDB example repository.
This tutorial takes approximately 15 minutes to complete.
To get the most out of this tutorial, make sure you have an understanding of:
To use DuckDB with Airflow, install the DuckDB Airflow provider in your Astro project. This will also install the newest version of the DuckDB Python package.
Create a new Astro project:
Add the DuckDB Airflow provider to your Astro project requirements.txt file.
If you are connecting to MotherDuck, the DuckDB cloud service, you need to use the amd64 version of Astro Runtime to prevent package conflicts. In this case, replace the FROM statement in your Dockerfile with the following line:
If you are only using DuckDB locally, you do not need to modify your Dockerfile.
You can use the duckdb Python package directly in your @task decorated tasks. This method does not require you to configure an Airflow connection.
Start Airflow by running astro dev start.
Create a new file in your dags folder called duckdb_tutorial_dag_1.py.
Copy and paste the following DAG code into the file:
This simple DAG passes a pandas DataFrame from an upstream task to a downstream task. The downstream task uses the DuckDB Python package to create and query a table in DuckDB. You can control the database you connect to by changing the string in the duckdb.connect() function:
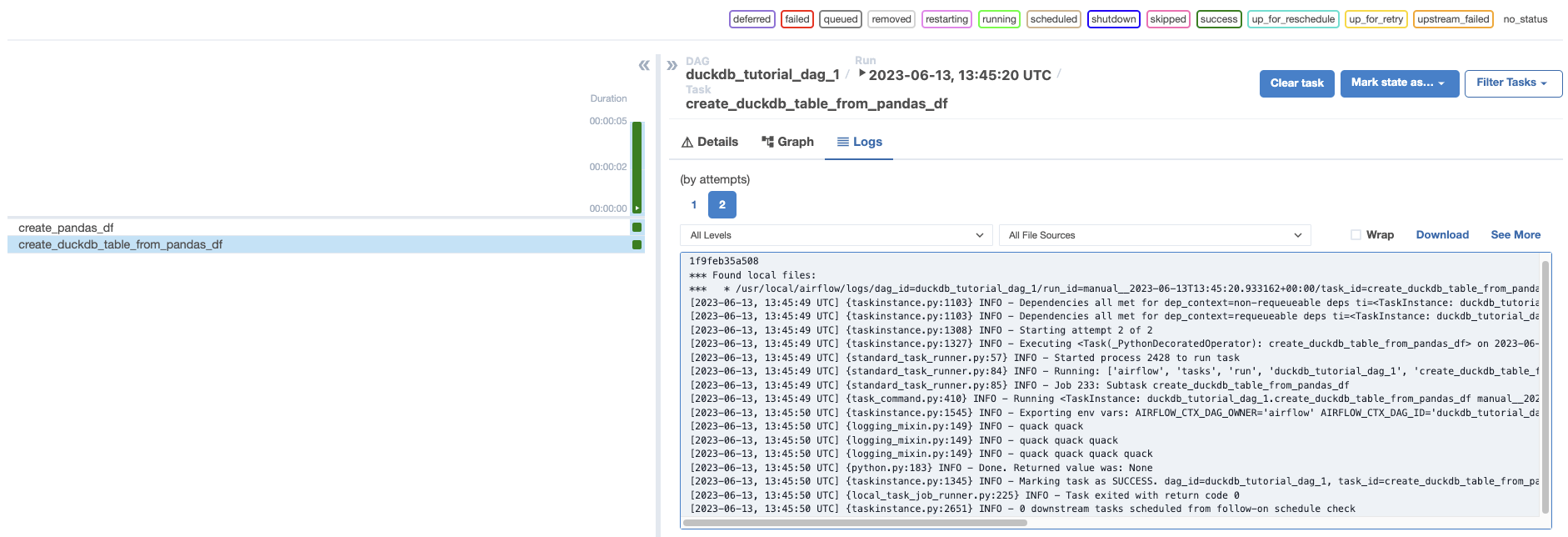
duckdb.connect("")).duckdb.connect("include/my_garden_ducks.db"))duckdb.connect(f"motherduck:?token={YOUR_MOTHERDUCK_TOKEN}")).duckdb.connect(f"motherduck:{YOUR_DB}?token={YOUR_MOTHERDUCK_TOKEN}"))Open Airflow at http://localhost:8080/. Run the DAG manually by clicking the play button, then click the DAG name to view the DAG in the Grid view. In the logs for create_duckdb_table_from_pandas_df, you will find a quack for each duck in your garden.
Next, you will create a DAG that instead uses the DuckDB Airflow provider. To use the provider, you will need to define an Airflow connection to your DuckDB database.
In the Airflow UI, go to Admin -> Connections and click +.
Create a new connection named my_local_duckdb_conn using the following information:
my_local_duckdb_conn.DuckDB.include/my_garden_ducks.db.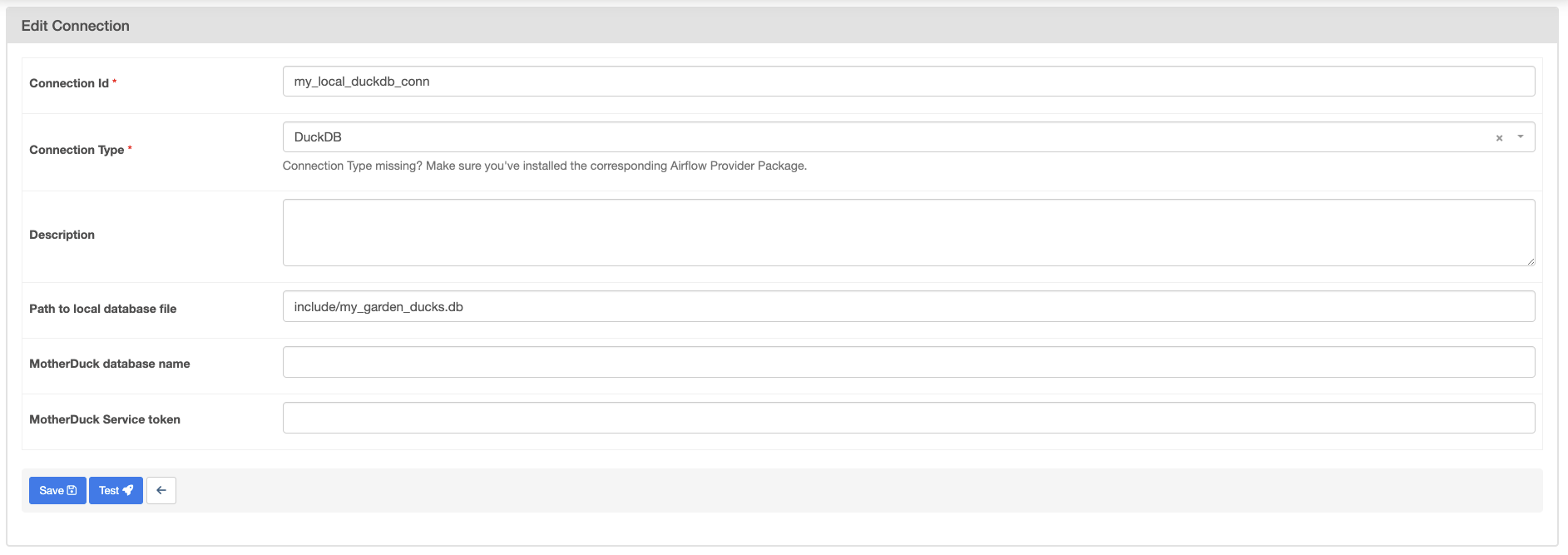
Click Save. Note that you cannot currently test a connection to DuckDB from the Airflow UI.
Info
If you are connecting to MotherDuck, you will need to add your MotherDuck Service token in the MotherDuck Service token field and leave the Path to local database file field empty. Optionally, you can add a MotherDuck database name in the MotherDuck database name field. The default name is the default MotherDuck database (
my_db).
Create a new file in your dags folder called duckdb_tutorial_dag_2.py.
Copy and paste the following DAG code into the file:
This simple DAG will query all information from a table in a DuckDB instance. Make sure the table you are querying exists in the DuckDB instance you specified in your DuckDB connection.
Open Airflow at http://localhost:8080/. Run the DAG manually by clicking the play button.
Info
You can use the DuckDBHook to create custom operators to modularize your interactions with DuckDB. You can find an example of a custom DuckDB operator for ingesting Excel files here.
Congratulations! You successfully used DuckDB with Airflow. Quack!