DAG Factory is an open source tool managed by Astronomer that allows you to dynamically generate Apache Airflow® dags from YAML. While Airflow dags are traditionally written exclusively in Python, DAG Factory makes it easy for people who don’t know Python to use Airflow.
This guide provides a complete walkthrough of using DAG Factory package to build production-ready pipelines in a modern Airflow project. You will learn to install the library, structure your project according to best practices, and define a multi-task pipeline entirely in YAML. The example demonstrates powerful features like using the TaskFlow API, organizing tasks with task groups, and passing data between tasks, all from your configuration file. By the end, you’ll be ready to apply these patterns to your own dynamic dags.
DAG Factory can be used with all Astronomer products and any Apache Airflow installation. To view the source code of the project, have a look at the dag-factory GitHub repository.
While writing dags directly in Python is powerful and flexible, it’s not always the most efficient approach for every use case. DAG Factory offers a configuration-driven alternative where you define the structure of your pipelines in YAML. This is particularly useful in several key scenarios:
YAML is often more approachable than Python. DAG Factory allows team members like analysts or junior engineers, who may not be Airflow experts, to create and manage their own dags with a simplified, declarative syntax.
If you have dozens of dags that follow the same pattern (like a standard extract-and-load job), DAG Factory is ideal. You can create a standard template and then generate numerous dags just by changing the parameters in a YAML file, which reduces code duplication and simplifies maintenance.
DAG Factory helps you separate the what from the how. The YAML clearly defines the dag’s structure and dependencies, while the underlying Python functions handle the actual business logic. This makes your dags easier to read at a glance and your Python code more modular and testable.
While DAG Factory offers significant advantages for some use cases, there are scenarios when using other ways of dag authoring like writing dags directly in Python are more appropriate.
When your data pipelines require complex conditional logic, branching or sophisticated error handling that goes beyond what YAML can express cleanly, native Python is generally the better approach. Additionally, YAML-based dags can be more challenging to debug compared to native Python code, as you are missing extensive logging or step-through debugging capabilities. Finally, your way of orchestrating workflows should match your team environment, so consider existing expertise.
While DAG Factory is a flexible product that supports all the main concepts of Airflow, newer features like asset-aware scheduling may work but are not as user-friendly or as well integrated as others.
To get the most out of this tutorial, you should have an understanding of:
First, create a new project directory and initialize an Astro project using the Astro CLI.
The init command creates a standard Airflow project structure. Since this tutorial focuses on DAG Factory, let’s remove the example dag that’s included by default.
Next, add the dag-factory library as a project dependency. Open requirements.txt and add the following line:
Now, start your local Airflow environment. The Astro CLI will build your project, installing dag-factory in the process.
Once the project is running, the Airflow UI should open automatically at http://localhost:8080 and you will be presented with an empty dags list.
A key to building a maintainable and performant Airflow project is proper organization. While you could put all your YAML configs, Python scripts, and SQL files into the dags/ folder, this can quickly become messy and put unnecessary strain on the dag processor.
Astronomer recommends placing Python, SQL, and other scripts that are not dag definitions in the include/ folder. Files in this folder are available to your dags but are not parsed by the Airflow dag processor, which reduces overhead and improves performance.
For this tutorial, we’ll use a structure that is also a great starting point for real-world projects:
dags/: This folder will contain only the YAML configuration files and the Python script that generates the dags from them. This keeps all dag definitions encapsulated.include/: We will create a tasks subfolder here to hold the Python functions that our operators will call. Any other supporting scripts (e.g. SQL queries) would also live in sub-folders within include/.We will apply this principle in the next steps.
For larger projects with a mix of dynamically generated and standard Python dags, consider organizing further. For example, you could create a dags/configs subfolder to hold all your DAG Factory YAML files, keeping them separate from your other .py dag files.
To separate our business logic from the rest of our orchestration logic, create a new folder named tasks inside include. There, we’ll add Python scripts that define the functions our YAML-based pipelines will call in the next steps.
Our example dag will orchestrate a simple pipeline using both a PythonOperator using the TaskFlow API and a BashOperator using the traditional operator.
DAG Factory supports both traditional operators and the modern TaskFlow API. This tutorial targets Airflow 3.x and will use the TaskFlow API decorator syntax whenever possible.
Before defining the dag in YAML, let’s write the Python functions that our tasks will execute. Following our plan from Step 2, we’ll place these functions in the include/tasks/ folder.
Create a file named include/tasks/basic_example_tasks.py with the following content:
Design your Python functions to be small, self-contained, and independently testable, which aligns with best practices for both DAG Factory and general Airflow development.
Now we can create the YAML definition for our dag. Create a new YAML file in the dags folder named basic_example.yml and add the following content:
This YAML file defines the dag’s structure and its tasks. Note how +extract_data_from_a and +extract_data_from_b are used to pass the return value of the extract tasks to the store_data task, and how Jinja templating ({{ logical_date }}) is used to pass the logical date.
The final step to make our dag appear, is to create the Python script that Airflow will parse. This script uses the DAG Factory library to find our YAML file and generate the actual Airflow dag object from it. This approach gives you full control over the generation process and allows for extensive customization in advanced use cases.
Create a Python file named dags/basic_example_dag_generation.py with the following content:
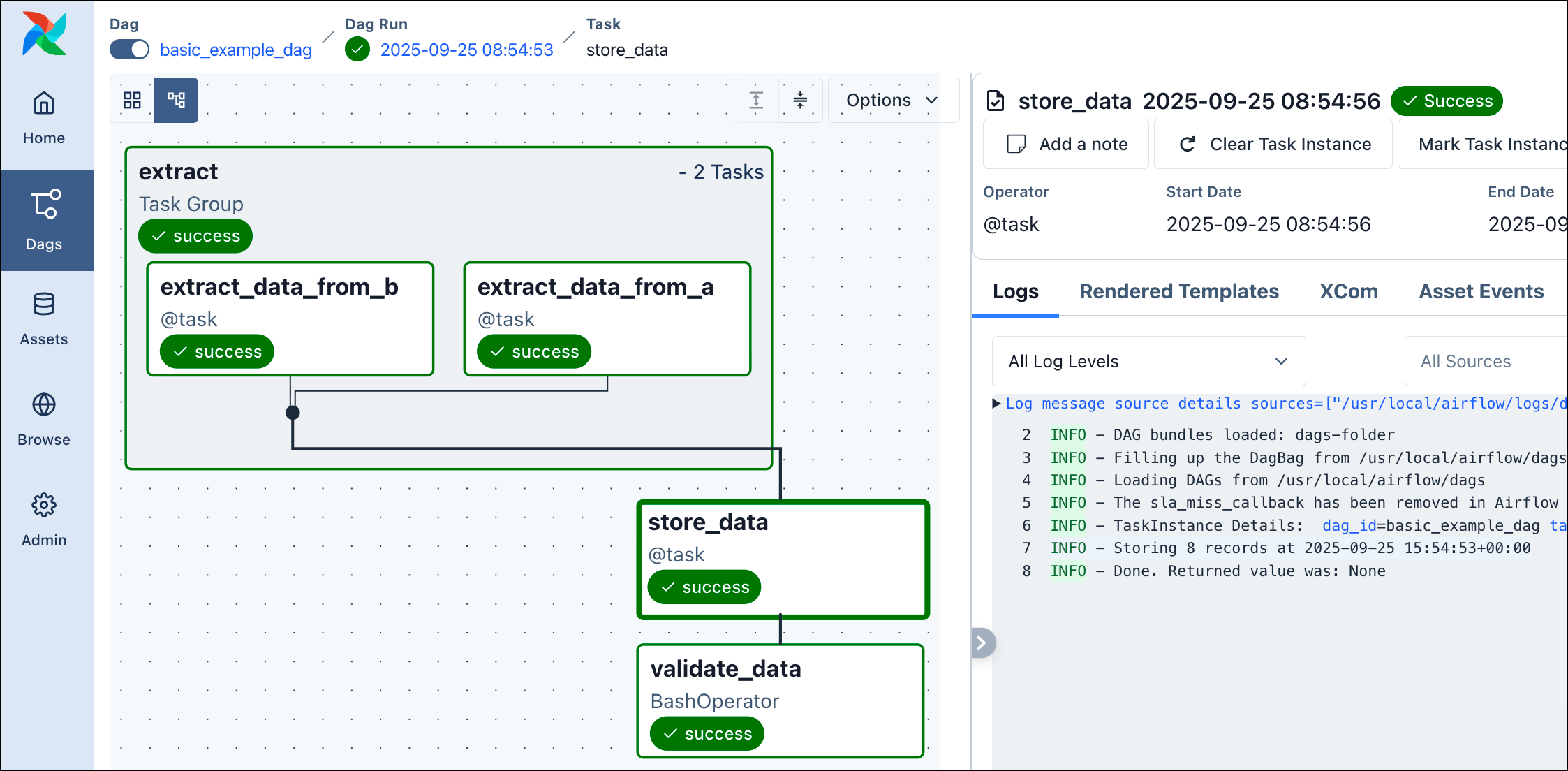
Once the dag processor parses this file, your dag with the ID basic_example_dag will appear in the UI. It has 4 tasks in its pipeline, 2 of them within a task group:
extract_data: Uses the TaskFlow API to call the _extract_data function from our include/tasks/basic_example_tasks.py script. We create 2 different tasks in this scenario. Both return a list of numbers.store_data: Uses the TaskFlow API to call the _store_data function from our include/tasks/basic_example_tasks.py script. As you can see, to pass parameters with this approach, just set them with the appropriate name directly in the YAML configuration. With +extract_data we tell DAG Factory to reference the return value of the extract_data task. Also as shown in the example, you can use Jinja templating including variables, macros and filters.validate_data: Here, we use the classic approach to use the BashOperator, just printing the sentence data is valid.The load_yaml_dags function is responsible for generating the dags. You can point it to a specific file, or to a folder that it will scan recursively for .yml or .yaml files. It uses the provided globals_dict to add the generated dags to the Airflow context. For more options, see the official documentation.
With this, you already know the basics of how to orchestrate a dag with YAML, including using task groups, passing data between tasks, using the TaskFlow API and classic operators, and setting basic dag attributes like the schedule or tags.
Dags defined with DAG Factory automatically receive the dagfactory tag. Also, if you select Dag Docs from the individual dag view, it will by default show the YAML file that created the dag, which is very useful for debugging.
This is a great starting point, and the following steps will cover more advanced features to prepare your DAG Factory knowledge for real-world use cases.
Now, let’s explore one of Airflow’s most powerful features, asset-aware scheduling, and how to implement it using DAG Factory. We will create two dags: a producer that updates an asset, and a consumer that runs whenever that asset is updated.
First, let’s create the Python functions that our tasks will execute. These functions will fetch data from an API, save it to a file, and then read it back.
Create a new file named include/tasks/asset_example_tasks.py with the following content:
include/tasks/asset_example_tasks.py
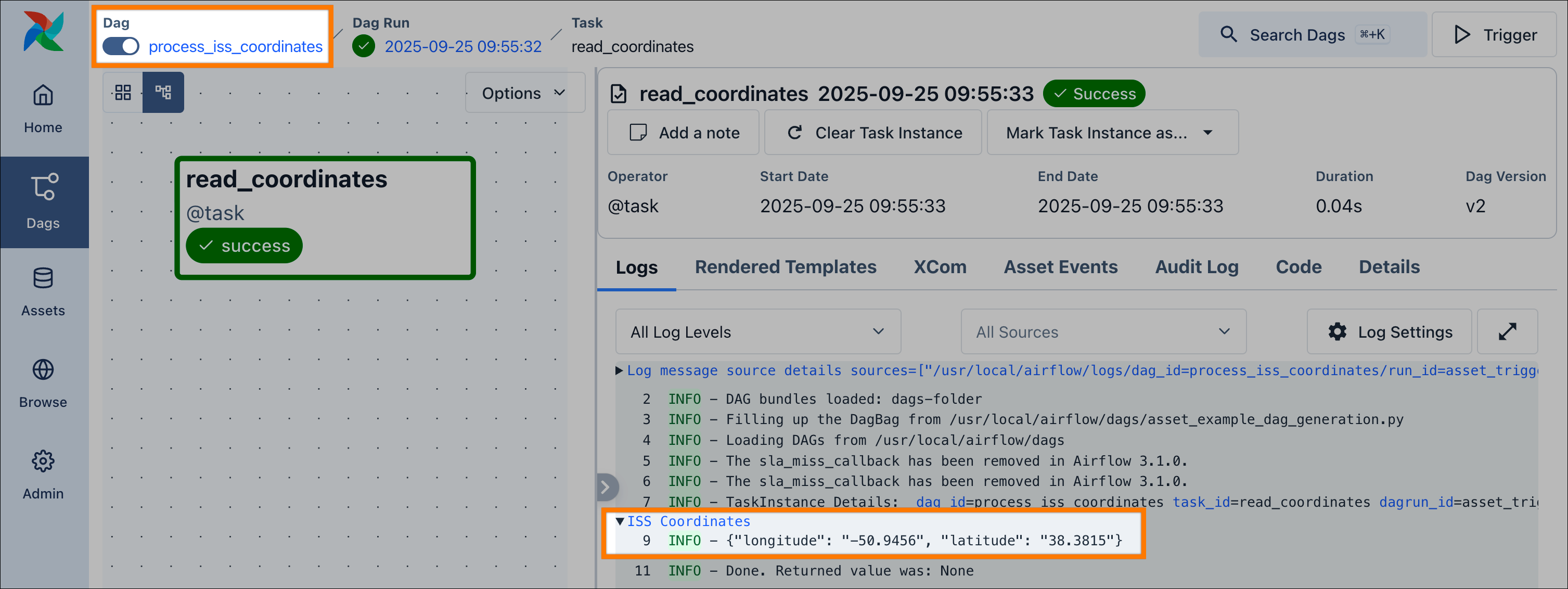
The _update_iss_coordinates function retrieves data from an API and writes it to a file, while _read_iss_coordinates reads this file and prints the content to a dedicated log group.
Now that we have our Python logic, we can define the two dags that will orchestrate it. Create a new YAML file at dags/asset_example.yml:
This single YAML file defines both the update_iss_coordinates (producer) and process_iss_coordinates (consumer) dags. For the producing dag we define an outlet of type airflow.sdk.Asset and name it iss_coordinates. The consuming dag then uses this same asset identifier for its schedule attribute, which creates the dependency.
Also, take note of the YAML top-level default block. This configuration affects all the dags defined in the YAML file, allowing you to share standard settings and configurations, for improved consistency, maintainability and simplicity.
Finally, to generate these dags in Airflow, we need to create a corresponding generator script. Create a new file named dags/asset_example_dag_generation.py with the following content:
dags/asset_example_dag_generation.py
And that’s it! Once the scheduler parses this file, you will see two new dags in the Airflow UI, connected by the iss_coordinates asset. When you run the update_iss_coordinates dag, the process_iss_coordinates dag will be triggered automatically upon its completion.
For a simpler approach to creating one dag with one task updating an asset, you could use @asset syntax, adding @asset(schedule="@daily") directly to the _update_iss_coordinates function in your Python file. This would allow you to remove the update_iss_coordinates dag definition from your YAML entirely. This tutorial defines both in YAML to fully demonstrate how DAG Factory handles asset producers and consumers.
In the previous steps, we used a dedicated Python dag generation script for each dag to parse the YAML with DAG Factory. This is a useful approach for maximum control over the generation process, and to avoid any unexpected workload when teams work with many YAML files.
However, it also adds complexity. The load_yaml_dags function therefore also supports a more pragmatic way, to parse all YAML files in your dags folder recursively. To illustrate this, delete the two generator scripts dags/basic_example_dag_generation.py and dags/asset_example_dag_generation.py. Then create a new file dags/dag_generation.py:
In this particular case, we need to add the dag import as an indicator for Airflow, to not skip this file during parsing. You will notice, the result will be the same as before, and all additional YAML files added will now be automatically processed.
When searching for dags inside the dag bundle, Airflow only considers Python files that contain the strings airflow and dag (case-insensitively) as an optimization. Because of these optimizations, you might need to add the dag import to ensure your file is parsed. To consider all Python files instead, disable the DAG_DISCOVERY_SAFE_MODE configuration flag.
In case you want to outsource your YAML definitions, you can overwrite the dags_folder argument when calling the load_yaml_dags function to set a custom folder to process recursively.
As you create more dags, you’ll want to avoid repeating the same configuration. DAG Factory includes powerful features for centralized configuration and inheritance to help you keep your dag definitions clean, consistent, and easy to maintain across your project.
This feature allows you to set default values for both dag-level arguments (like schedule) and task-level arguments (like retries via default_args).
In our dags/asset_example.yml file, you already discovered one way to configure dags in a centralized way within the YAML definition:
With this approach both dags, update_iss_coordinates and process_iss_coordinates, will use the start_date from the default block. This feature becomes even more powerful, when using global defaults in combination with inheritance.
To illustrate this, let’s imagine a real-world scenario with a set of company-wide data pipeline standards:
start_date of 2025-09-01.astronomer, unless they belong to a specific department.@daily), unless specified otherwise.DAG Factory automatically looks for a file named defaults.yml in your dags folder and applies its configuration to all dags within that folder and its subfolders. This creates a single source of truth for your global defaults.
load_yaml_dags uses the same default path for both the configurations and the YAML files: the path set as dags_folder. You can override only the path where DAG Factory looks for configurations, by setting the defaults_config_path parameter.
To implement our company standards, create a new file at dags/defaults.yml with the following content:
The real power of this feature comes from inheritance. DAG Factory applies defaults.yml files hierarchically. A defaults.yml in a subfolder will inherit from its parent and can override any of the parent’s settings.
Let’s apply this to our scenario. We want to override the default owner for our Marketing and Finance departments, and also change the default schedule just for the Marketing department, to run dags at 1 AM rather than midnight for this department.
First, let’s create the folder structure:
Now, create dags/marketing/defaults.yml to set a new schedule and owner:
And for the Finance department, create dags/finance/defaults.yml to override only the owner:
Now that our defaults are in place, creating the actual dags is incredibly simple and clean.
Create dags/marketing/marketing_dag.yml:
And similarly, create dags/finance/finance_dag.yml:
Notice how concise these definitions are. We don’t need to specify start_date, owner, or retries because they are all handled by our layered defaults.yml files. This allows you to write minimal dag configurations while maintaining centralized control over your project’s standards.
In the Airflow UI, you will see two new dags, each with a different set of inherited properties:
marketing_dag: Inherits the schedule (0 1 * * *) and owner (astronomer-marketing) from its local defaults.yml, and retries from the global defaults.yml.finance_dag: Inherits the owner (astronomer-finance) from its local defaults.yml, and both the schedule (@daily) and retries from the global defaults.yml.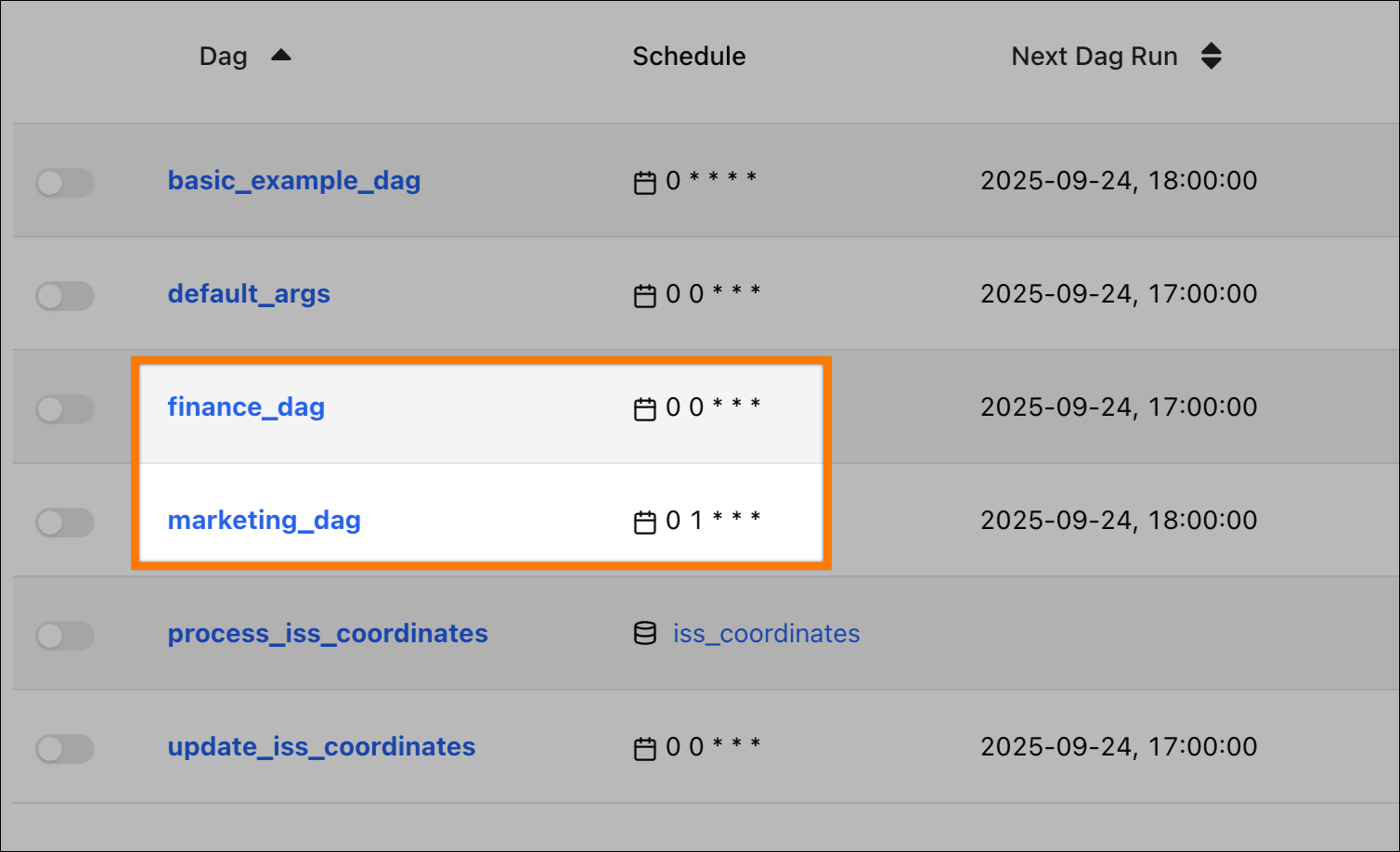
If any defaults.yml files are inside your dag_folder, DAG Factory might try to parse them as dags, which can cause errors in your task logs. To prevent this, keep dags_folder and defaults_config_path separate. Configuration inheritance still works as expected, and these errors are non-critical.
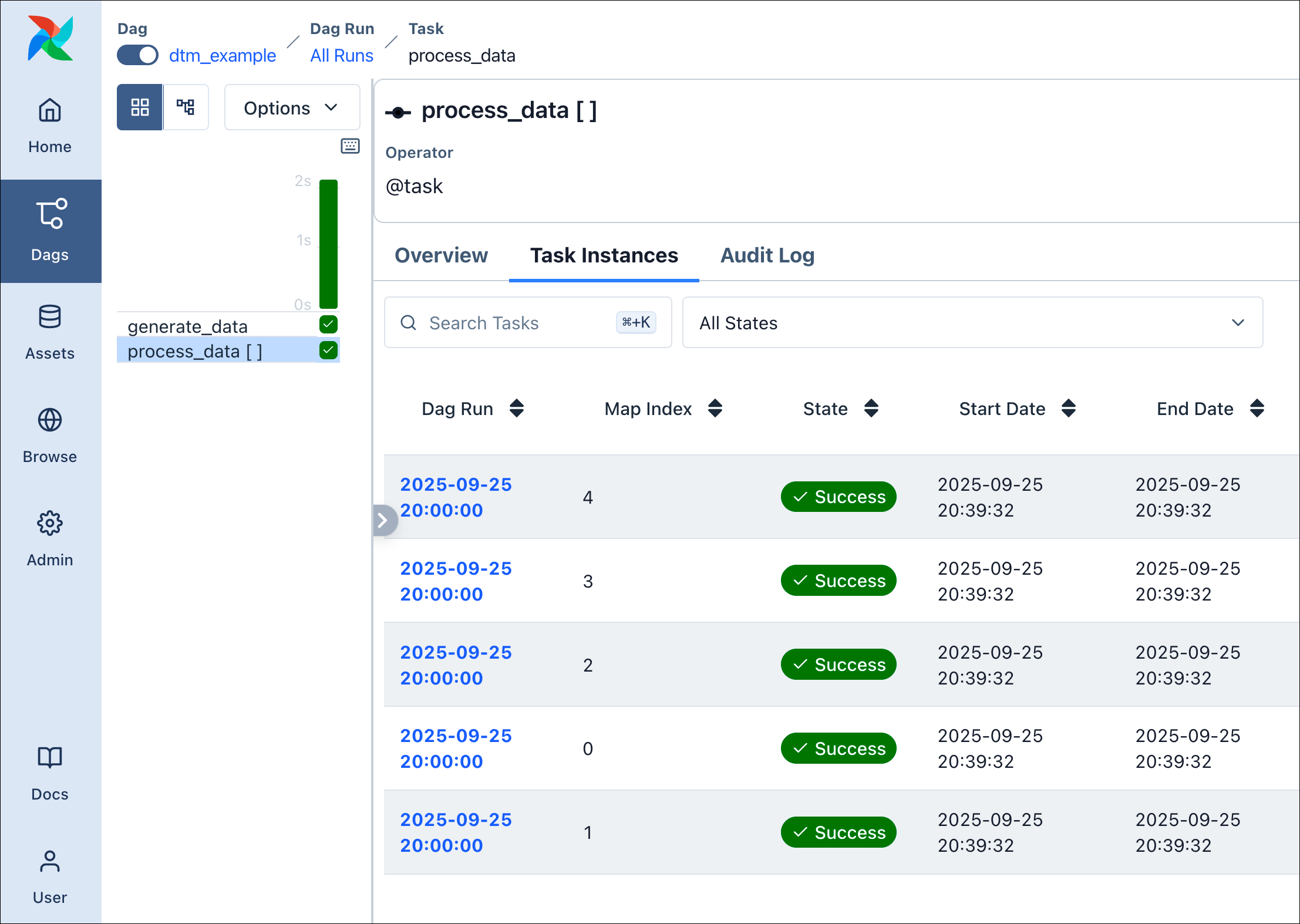
DAG Factory also supports dynamic task mapping, to dynamically generate parallel tasks at runtime. The following example shows how to apply this principle using the TaskFlow API. Let’s assume we have the following Python functions defined in include/tasks/dtm_tasks.py:
We can now simply reference arguments under partial and expand in our YAML, to let DAG Factory apply dynamic task mapping:
With this, we will use the output of generate_data to generate parallel task instances.
The examples above show how to use DAG Factory to create dags based on static YAML files. For use cases where you’d like to create several dags with a similar structure it is possible to create them dynamically based on a template YAML file to avoid code duplication.
Creating a dag dynamically with DAG Factory simply means that you use Python code to create the YAML configurations instead of writing them manually.
There are two files that you need:
Since Airflow uses Jinja2 internally already, we can leverage this library for a more robust generation process.
The template YAML file provides the structure for all the dags you will generate dynamically with placeholders for values that vary in between the dags. Create a file called include/template.yml:
include/template.yml
The Python script reads the template YAML file, replaces the placeholders with the actual values, and writes the resulting YAML files to the dags directory. Place this script in the top-level of your project for now. You can run this script manually to generate your dags for local development or automatically as part of your CI/CD pipeline.
generate_yaml.py
As a result, you will see the dynamically generated dags/dynamic_dags.yml file:
dags/dynamic_dags.yml
In this tutorial, you’ve journeyed from defining a single dag in a YAML file to building a complete framework for dynamically generating your pipelines.
You’ve learned how to:
defaults.yml files for inheritance.Whether your goal is to empower analysts, standardize repetitive ETL jobs, or simply separate your pipeline’s structure from its logic, DAG Factory provides a robust, configuration-driven approach to Airflow development.
To continue your journey, explore the official DAG Factory repository, which contains many more examples and advanced use cases. You now have all the tools to start building your own dynamic dags.